最近想着复现之前矩阵杯的一道分析pyd的题目,难度实在是对我来说有点大,看Writeup都费劲,所以想自己写源码再生成一个简单的pyd再分析一下,我们这篇文章来学习一下Python逆向当中的一些特殊文件
Pyc
pyc文件的全称是Python Compiled Bytecode File
关于Pyc的结构,我有在marshal模块和pyc的关系当中学习过了
pyc与marshal – Arnold’s Blog (arnold66.top)
当然,我觉得在Python逆向当中,学习到这个程度可能已经够了,这里再做一下简单介绍
pyc文件是由用 Python 编程语言编写的源代码生成的编译输出文件。当使用 Python 解释器运行py文件时,它会被转换为字节码以供执行。同时,编译后的字节码也会保存为 pyc 文件,以便以后在适用的情况下从缓存中重用。而无需在每次运行脚本时重新编译源代码。这可能会导致更快的脚本执行时间,尤其是对于大型脚本或模块。
pyc文件有保护源码的作用,我们看不到它的源码,但可以通过命令运行它。

Pyo
pyo文件的全称是Python Optimized Bytecode File
pyc文件,是python编译后的字节码(bytecode)文件。
pyo文件,是python编译优化后的字节码文件。pyo文件在大小上,一般小于等于pyc文件。如果想得到某个py文件的pyo文件,可以这样
python -O -m py_compile sample.py这里注意O要大写,没想到生成后还是pyc后缀的文件

优化的大小和不优化大小也是一样的,这种优化可能只优化一些特定的代码
那就没啥好说的了,跟pyc一样的逆向分析方法。
Pyd
pyd文件的全称是Python Dynamic Module
pyd文件是Python中一种特殊的二进制文件,主要用于在Windows操作系统上存放C或C++编写的Python扩展模块。这些扩展模块通过编译成.pyd文件,可以在Python环境中被导入和使用,从而提供比纯Python代码更高的执行效率。这种文件类似于Unix系统中的.so(共享对象)文件,它们的功能和用法都十分相似。
当然,python代码也可以打包为pyd。但是我猜测可能利用C或C++编写更多,因为可以达到提高代码执行效率的目的,python代码打包肯定是没有C和C++那么显著的。
我们先看Python代码打包成pyd的情况
创建一个setup.py文件,内容如下
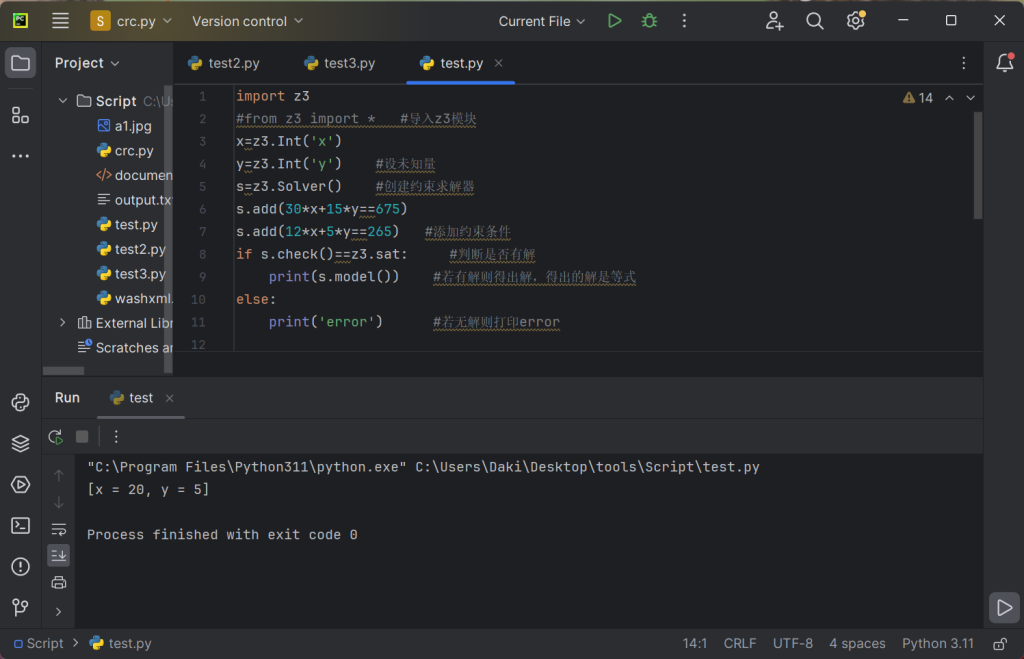
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("sample.py")
)然后我sample.py里面为了方便逆向分析,内容如下
def ADD(x,y):
x=x+10
y=y+10
sum=x+y
return sum
def SUB(x,y):
x=x-6
y=y-6
res=x-y
return res
def JUGE(x,y):
sum=x+y
if(sum==66):
print("Arnold!!!")
return 0然后再用以下命令即可生成pyd
python setup.py build_ext --inplace就可以成功生成pyd文件了


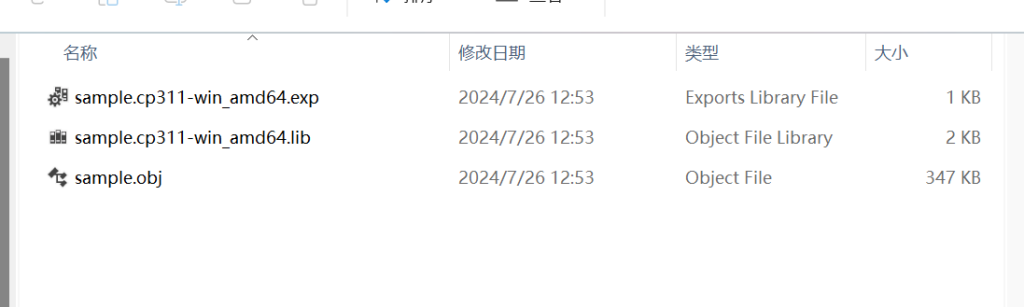
运行命令后会生成一个bulid文件夹,里面有两个文件夹,第一个内容就是pyd,第二个应该是关于C语言的,我们不关注这部分,我们看pyd。
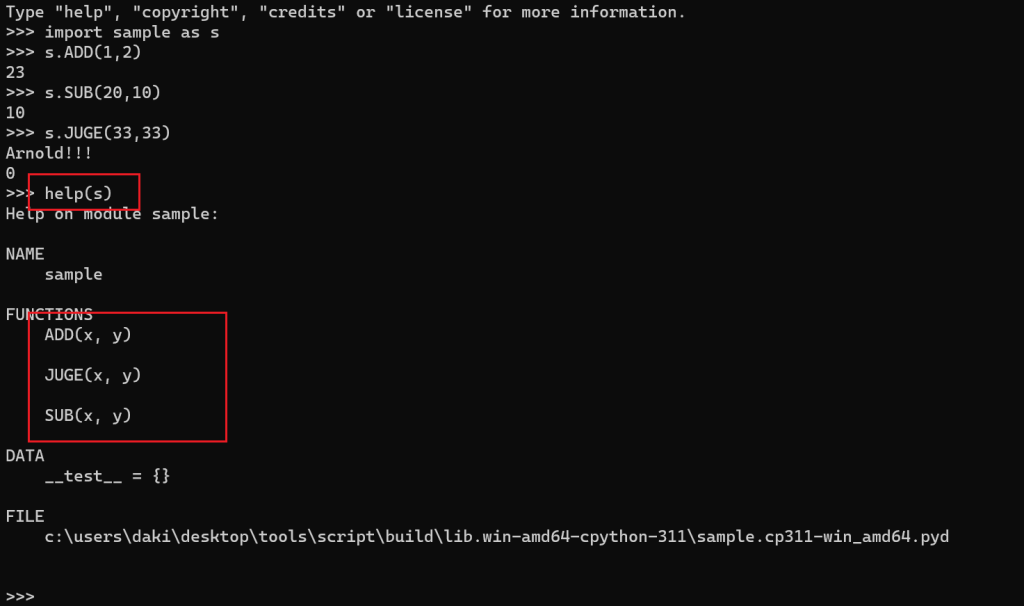
可以看到是可以正常作为Python的模块导入并且使用的,我们可以通过help来查看模块当中都有哪些函数。
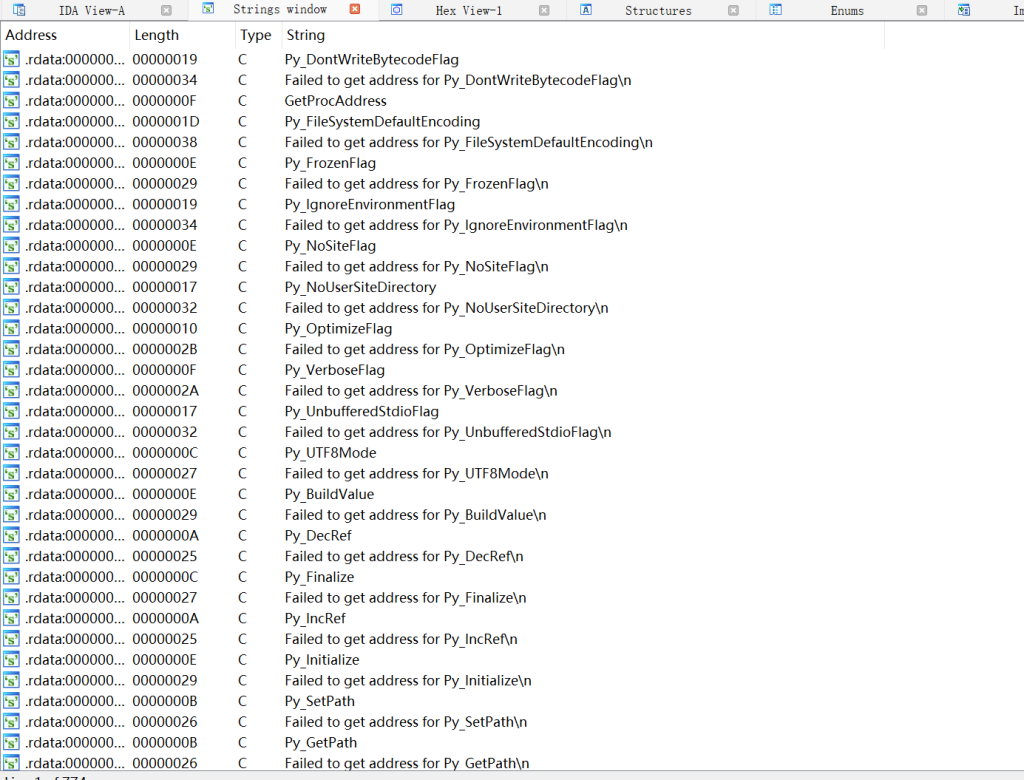
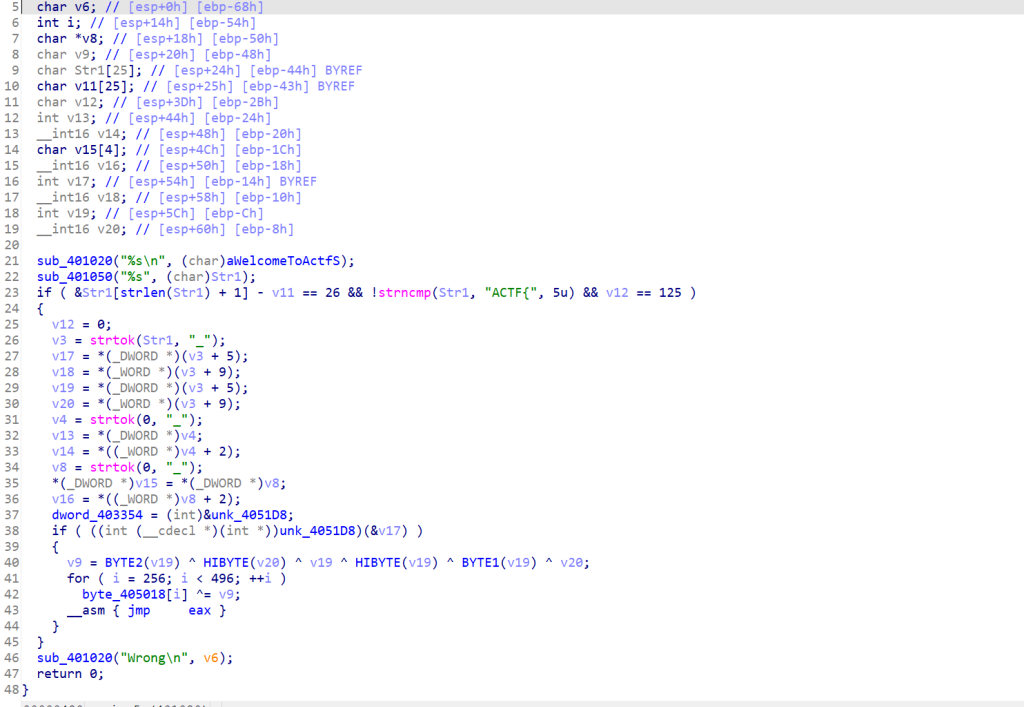
接下来再在IDA当中逆向分析pyd,我们可以在String窗口追踪到相应的函数,以ADD函数为例

函数有很多的混淆代码,根本难以发现逻辑点,这也是pyd为啥难以分析的原因,仔细找,发现了一个相关的API函数,很明显是执行加法的运算
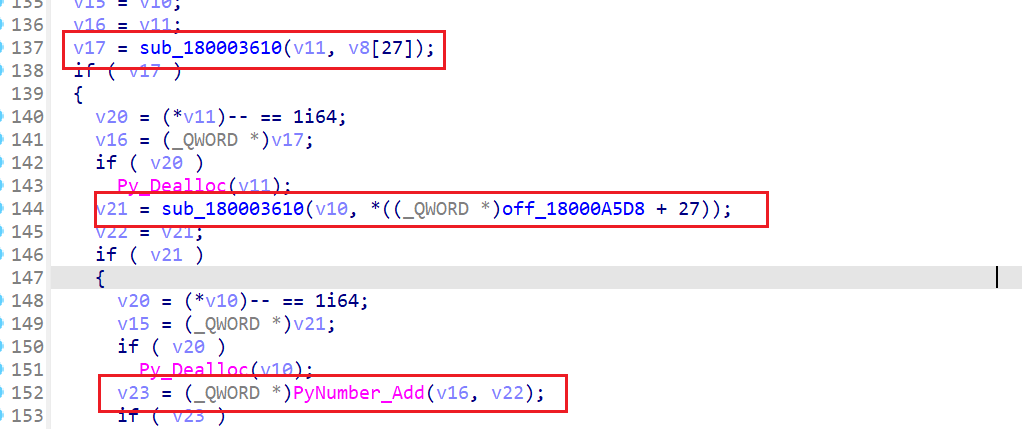
再通过这个API函数,我们定位sub_180003610函数,点进去发现确实是ADD函数的大概逻辑,但是这是在我们知道源代码的情况下分析的,倘若不知道源代码,其逆向分析的难度你看一下这些代码就知道并不简单。
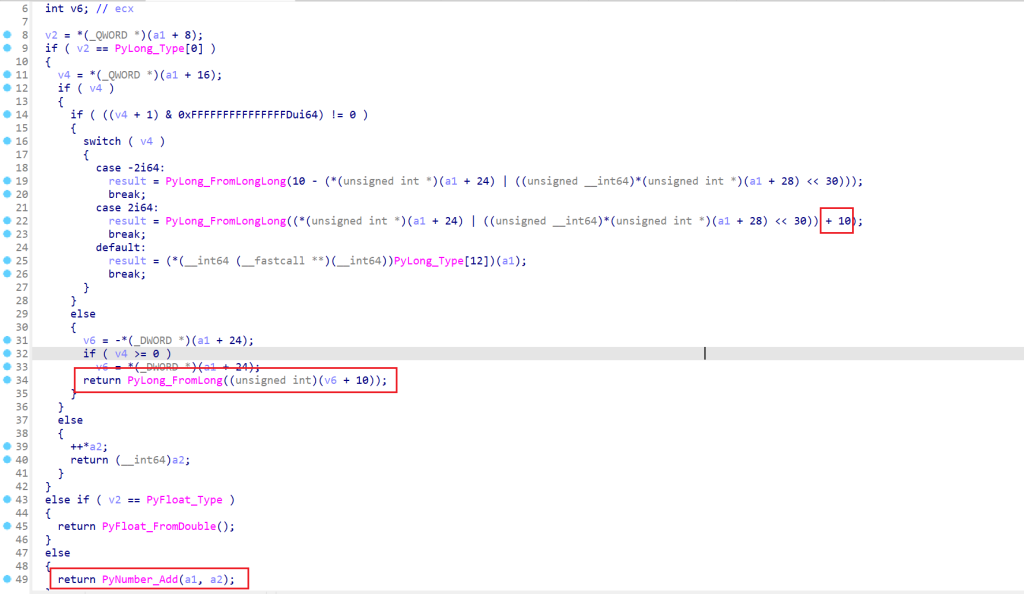
SUB函数的分析过程和ADD函数一样
那么我就想修改一下SUB或者ADD函数的代码,去观察它们的区别来看往后我们逆向分析的时候关键看哪里,我把SUB函数和ADD函数改成了这样
def ADD(x,y,z):
x=x+10
y=y+8
z=z+4
sum=x+y+z
return sum
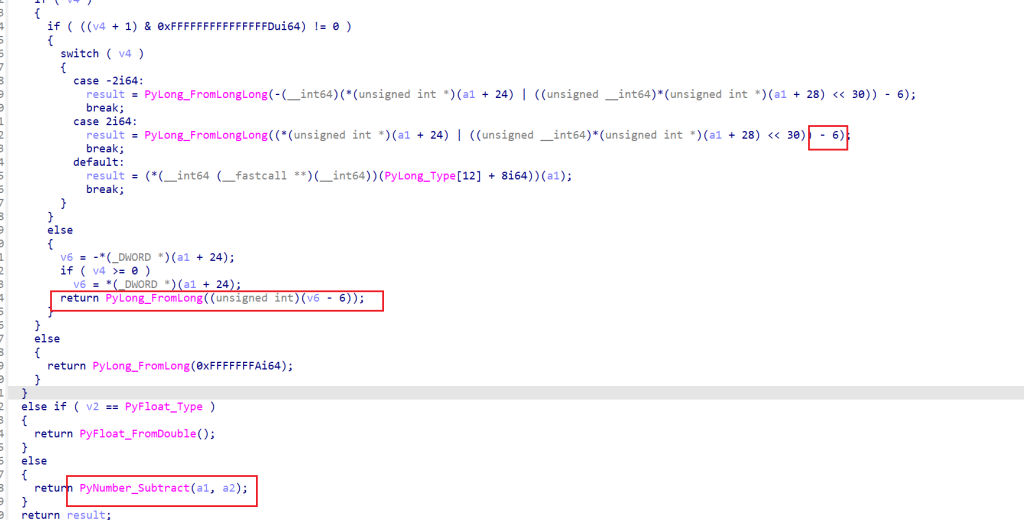
def SUB(x,y):
x=x-6
y=y-7
res=x-y
return resSUB函数的减去的数不同之后,传入关键函数的参数就多了一个
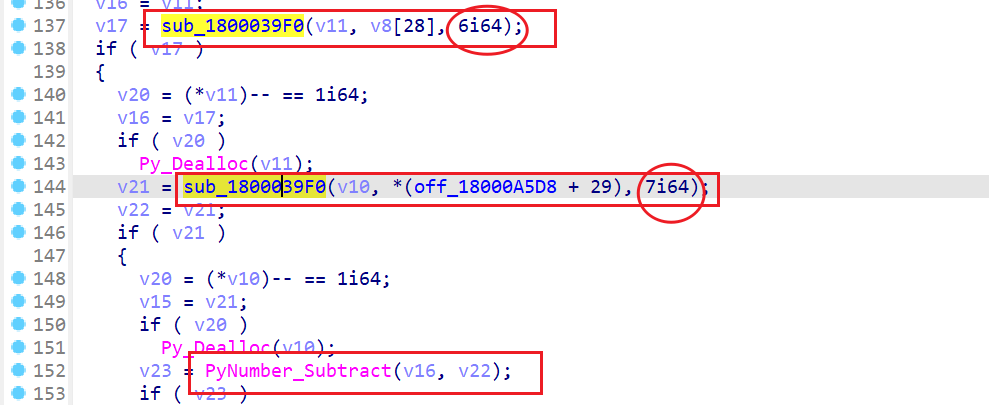
ADD函数也一样,并且多用了一个API函数来实现三数的相加,这些简单逻辑视乎都只用关注关键函数的return返回值的部分。
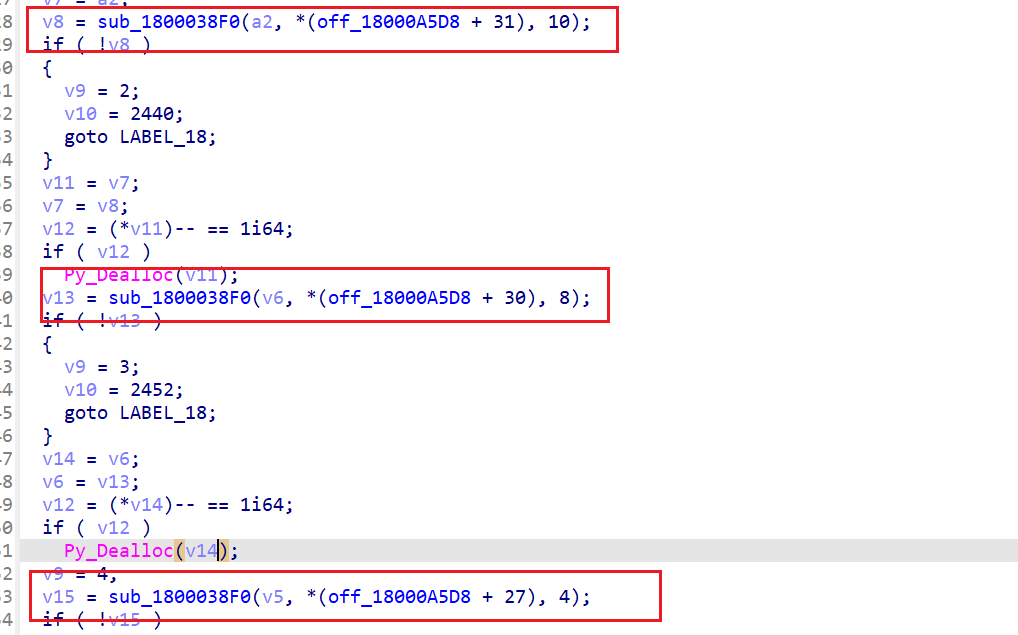
在修改了代码之后,还发现下面这个API函数PyErr_Format传入的这个位置的参数,就是我们分析的函数实际需要接收的参数的个数。

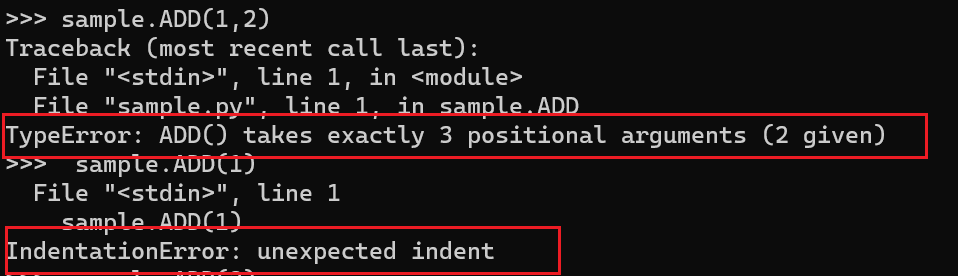
我们在Python中调用,并且只传入2个函数给ADD看看,应证我们的猜想是正确的
那么这两个简单函数在pyd中的呈现我们就看完了,接下来就看JUGE函数
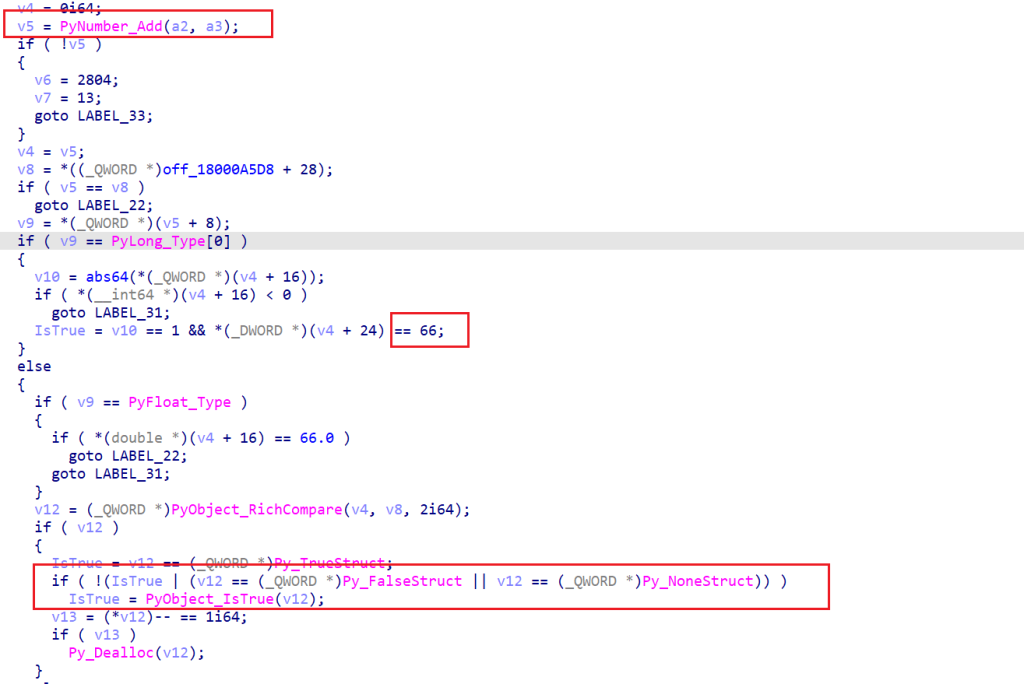
很容易就找到了JUGE函数的主要逻辑,第三部分的代码一般只要Python中出现If的判断语句都会有
这里的IsTrue变量就是一个标志,还有PyObject_RichCompare、PyObject_IsTrue等API函数可能也都是。
但是我有一个疑惑的点在于倘若判断成立,应该会输出”Arnold!!!”的字符串,但是函数里面找不到这样的操作,我认为打印函数可能是下面这个
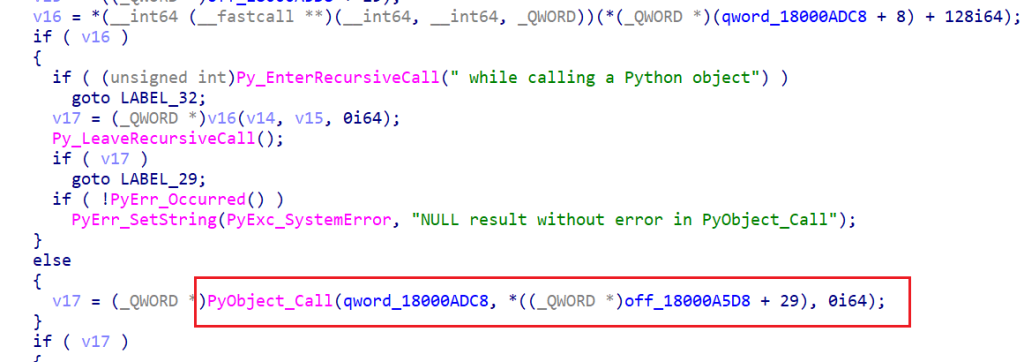
因为PyObject_Call这个API函数全局只调用了一次,但是我patch了一下,发现并没有什么影响,然后前面的跳转也试了patch一下,还是找不到哪里是打印函数的地方,算了在这里就打个问号先吧。
我还发现引用PyUnicode_InternFromString的函数,一般有一些关键字符串变量在里面,如图
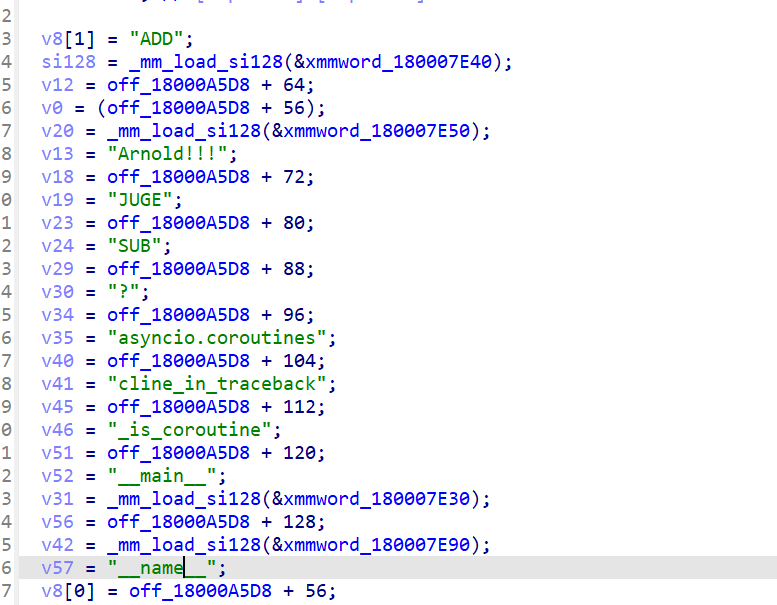
这里的字符串比如”Arnold!!!”如果被修改的话,是会有影响的。
在pyd逆向当中,因为CTF题目通常要得出flag,所以一般密文会以数组的形式存在,接下来我们探讨一下数组的形式在pyd文件当中的呈现,源代码如下
def ARRAY(x):
data=[11,66,5594,8742,645,31,4654,45,13,5312,151,21564,153,99,66,55,22,33,418]
if (data[x]==66):
print("alright!")
data[x]=66
data[6]=x
return 0这函数里面有一个长度为19的列表,再放到IDA中看看,很容易找到关键逻辑
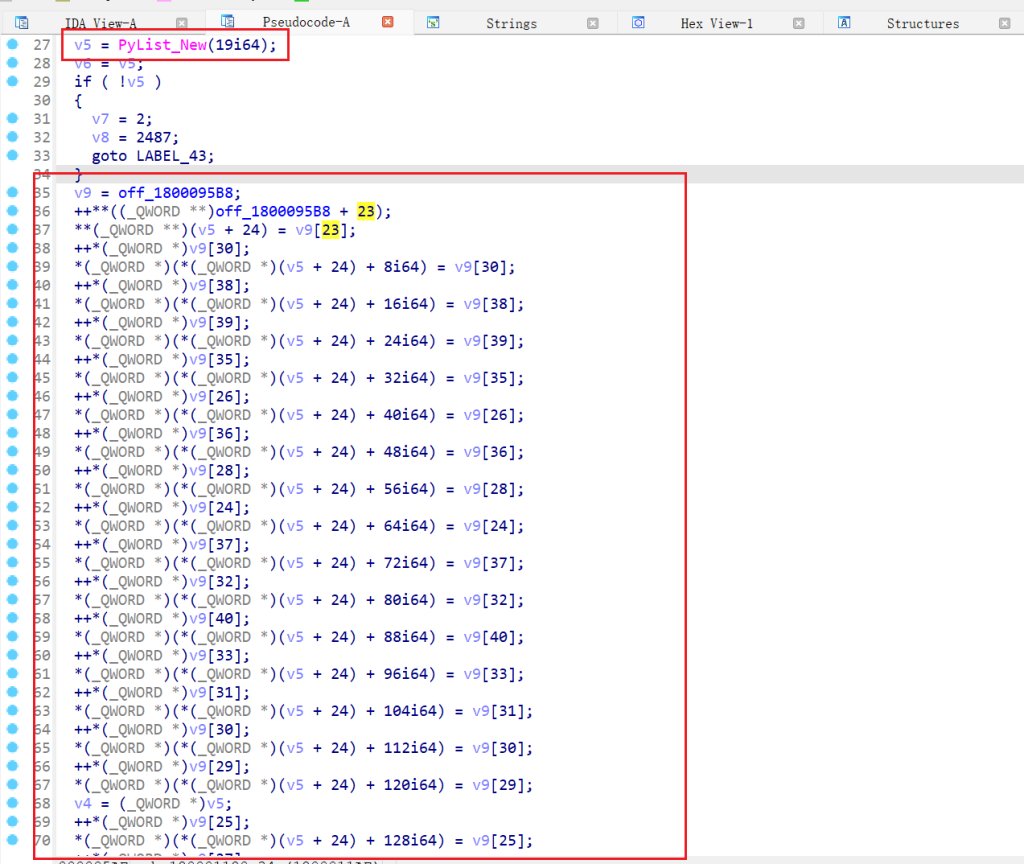
用一个API创建了一个列表,后面v5偏移每次加8,加到144,刚好是19个元素,但是这里没有显示列表当中的数据,找到PyUnicode_InternFromString函数的地方,也没有列表当中的数据
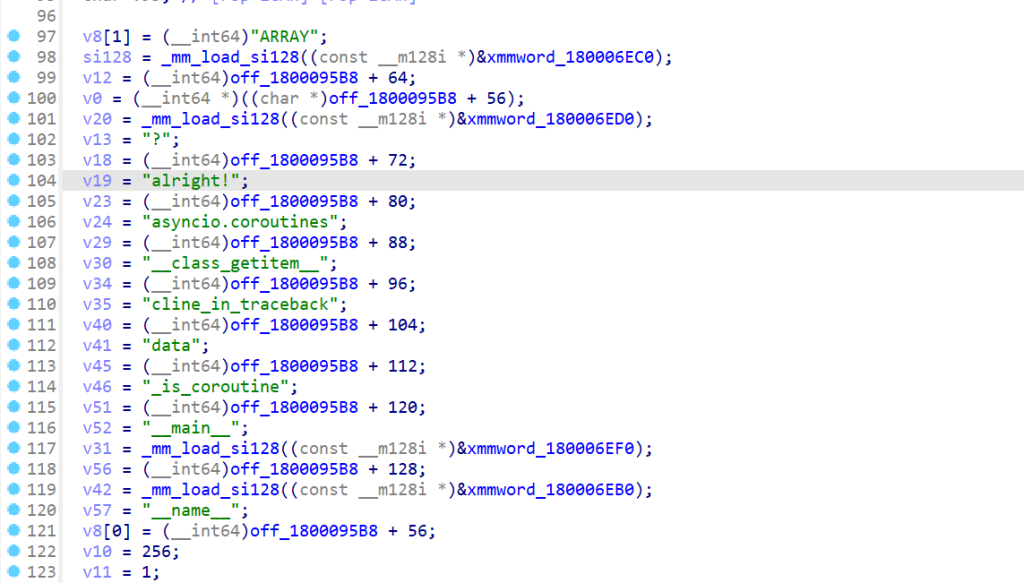
通过交叉引用可以发现列表当中的数据
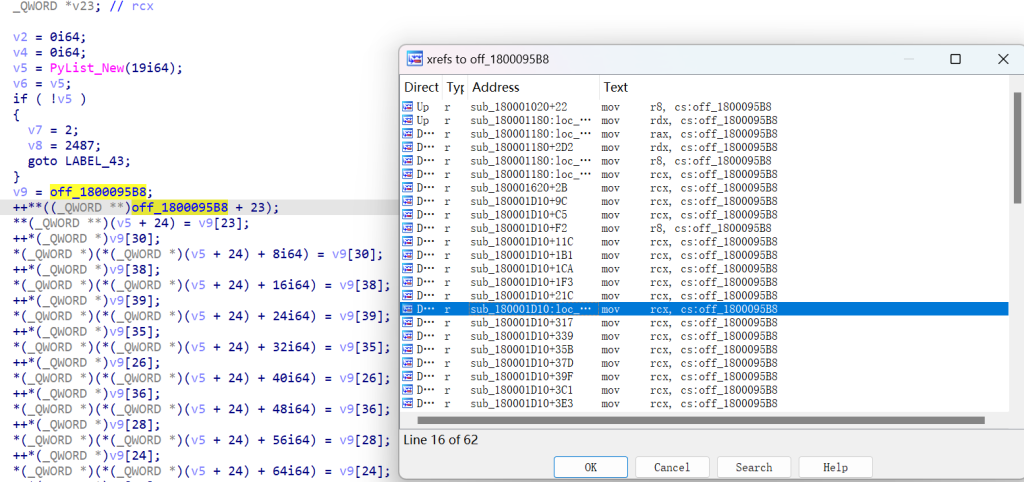

这里的数据从小到大排列,有很密集的PyLong_FromLong 函数,传入函数的参数就有我们列表当中的数据,我们看看如何确定列表数据的实际顺序
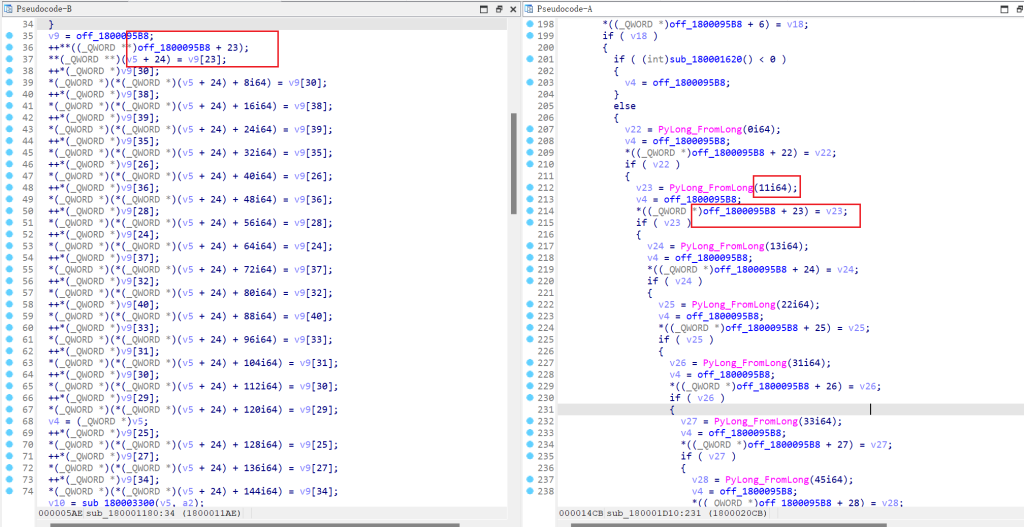
如图,左边第一个列表元素的索引为23,再看右边的索引,就能得到列表的第一个元素是11,这样我们就能得到列表的全部元素了。
这里还发现PyObject_SetItem函数一般用于设置列表索引的值,如下图
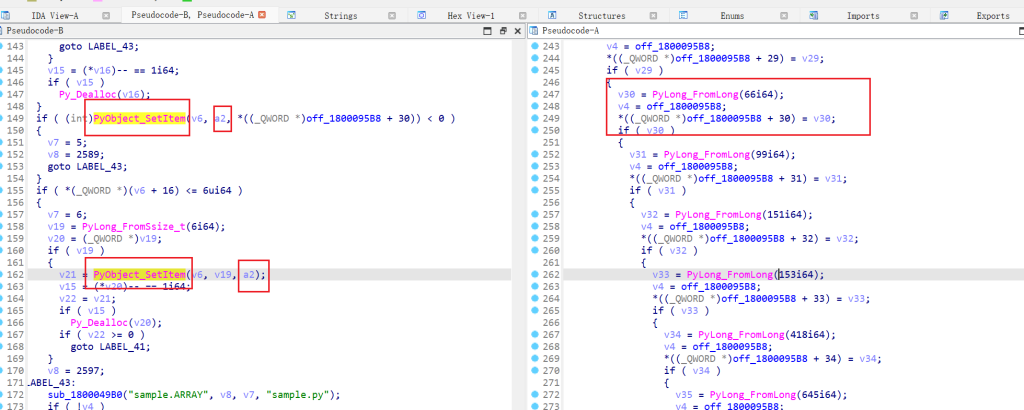
用了两次函数其实就相当于上面的Python代码
data[x]=66
data[6]=x目前为止就是我关于pyd的所有发现了,等学到了新知识再来补充。